System Architecture
(PAS, GN)
Document Contents
Overview of the Cluster Architecture
Architecture components
The cluster is divided into several components arranged in relatively independent layers.
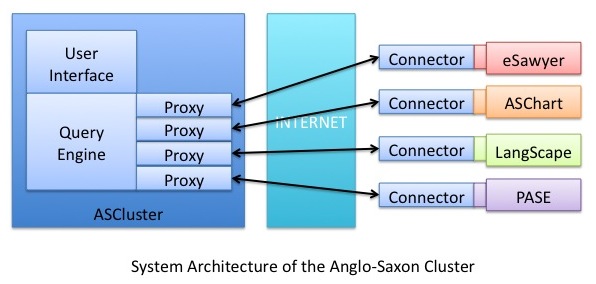
The above diagram shows the various layers and components that constitute the complete cluster:
- The user interface converts the inputs from the search form into a query message, sends it to the query engine and converts the result set in the query engine's response into HTML for display to the user.
- The query engine dispatches the query message to the constituent projects and merges their responses into a single message.
- The proxy acts like a local version of a connector. It converts the query messages from the query engine into XML and sends it over the network (using SOAP communication) to the remote connector.
- The connector is made of two parts:
- A generic SOAP wrapper: this reads the incoming XML message, converts it into a query messsage and sends it to the query processor.
- A project-specific query processor: this reuses the existing Anglo-Saxon project API or model layer to resolve the incoming query against the operational data source.
- The existing Anglo-Saxon web applications: ASChart, eSawyer, LangScape and PASE.
The user interface, query engine and proxies are installed on the same server. One of the key constraints of ASCluster requirements was to keep the code and data of the participant projects as much as possible. This decision was motivated by the need to minimise the complexity and duration of the development as well as the risk of destabilising live web applications. The architecture meets this constraint completely as the deployment of the lightweight connector code on the project servers is a stricly additive operation.
Layered architecture
Each layer knows only about the programming interface of the layer directly under it and makes minimal assumptions about the nature and the number of the 'clients' in the above layers. Inter-layer communication is also entirely stateless.
This type of layered architecture guarantees modular abstraction which in turn offers many benefits:
- Support for alternative and concurrent usages. The content of one layer can be substituted without affecting the one underneath or above it (as long as its interface remains the same). For instance the section on future possiblities of the Cluster explains what other applications can be envisaged by replacing the current web-based search form by remote widgets or SOAP clients embedded in external projects.
- Generalisability. The query engine does not attach a particular meaning to any element, such as a charter or a king, other than their structural description as defined in the physical data model. This model can be modified, extended or even replaced entirelywithout affecting the current architecture or the capabilities of the present implementation.
- Extendibility. Since the participation of an individual project in the pool of data sources is abstracted by the proxy and the connector, a project can readily be added or removed without any modification to the search engine.
- Independent and parallel development. The user interface and query engine were developed separately and any concern about their surrounding components was limited to the pre-established programming interface. Likewise the four connectors (ASChart, eSawyer, LangScape and PASE) were developed by four different people, in each case by the person with existing expertise about the internals of the particular project, and without any awareness of how the user interface or query engine work. These benefits brought by the architecture were particularly effective as the challenges of an integration project are not exclusively technical and intellectual but also human and logistical. It should be noted that the fastest development time for a connector was about a day of work.
System-wide query interface
As evidenced by the UML class diagram below, the object oriented design of the cluster makes extensive use polymorphism throughout the different layers.
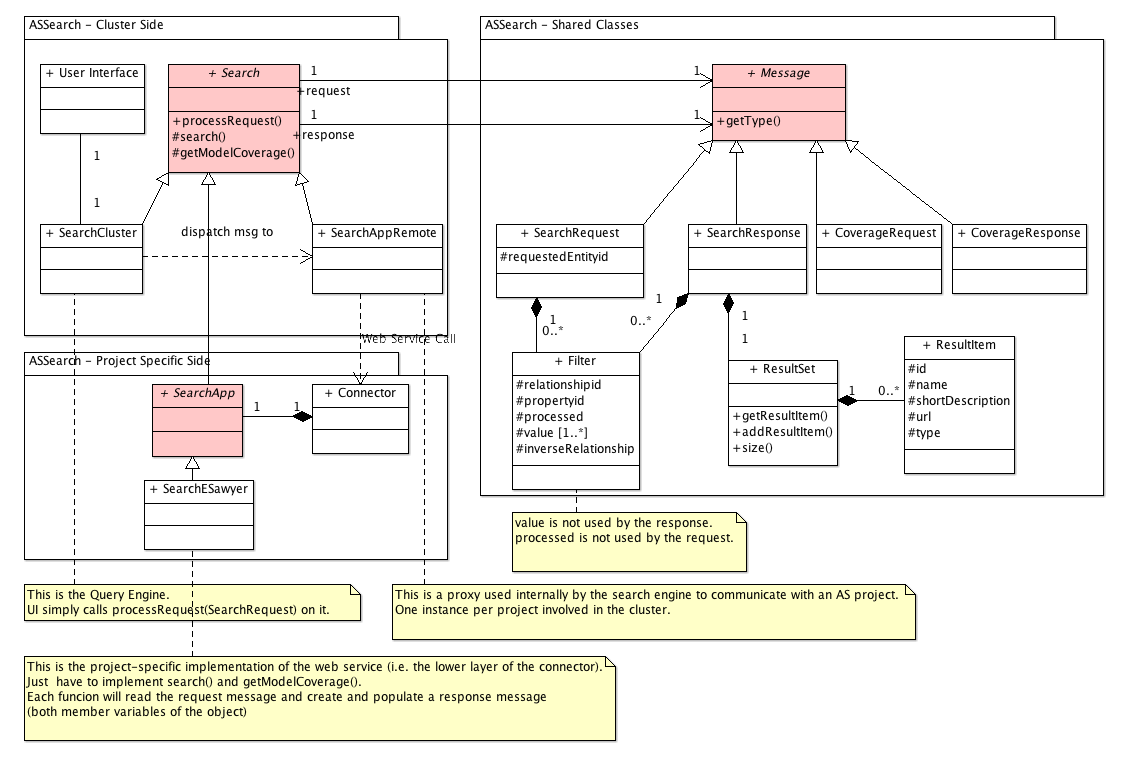
Indeed there is a generic query programming interface and language which is broadly understood at each level (although with some minor variations and obviously different realisations). For example, the core of the message created by the user interface to represent a complex query has exactly the same structure whether it is received by the query engine, the proxy or the connector.
One notable consequence of this design is the possibility, for instance, of connecting the query engine or even the user interface directly to a local connector. The user interface and the query engine currently communicate with each other via internal function calls within the same Java process. Once again, the use of a common interface throughout the whole architecture would allow us simply to place a connector on top of the query engine to decouple it from the user interface and make it available to other remote clients.
Query Engine
The query engine is the component responsible for distributing the query to all the participant projects and merging the results into a single response message.
This section describes the path followed by a simple query message during its journey through the cluster. It concretely illustrates how the different components in the architecture collaborate to respond to a search query coming from the user interface. It also explains why the query engine sometimes need to send two rounds of messages to the connectors.
You might find it helpful to run this query on our prototype before reading the description. The query language section may also be of interest.
- The search engine receives a query message from the user interface, for example 'give me all the charters wintessed by someone called Oswine and which contain a Promulgation Place clause'.
- The message is actually structured like this:
First query message
- requested entity: [CHARTER]
- filter 1: [WITNESSED_BY.NAME = { 'Oswine' }]
- filter 2: [HAS_CLAUSE.TYPE = { 'Promulgation Place' }]
- The message is sent in parallel to the local proxies of all the registered projects.
- Each proxy converts the query into an XML SOAP messsage and sends it over internet to the relevant connector.
- Each connector receives the message:
- LangScape: returns a message with an empty result set and specifies that filter 1 and filter 2 could not be processed because LangScape is not the authoritative project for information related to charter witnesses and clauses.
- ESawyer: responds like LangScape.
- PASE: uses its own data layer (rdb2java) to query the PASE relational database in order to find all the charters witnessed by Oswine. It returns their ids (along with their names, urls and descriptions) and also specifies that filter 1 was processed but not filter 2.
- ASChart: uses Lucene to query its XML dataset and find all the charters that contain an invocation. It returns their ids (along with their names, URLs and descriptions) and also specifies that filter 2 has been processed but not filter 1.
- The Query Engine discards responses from LangScape and ESawyer because they have not processed any of the filters.
- Before continuing it checks that all the filters have been processed by at least one connector.
- It takes the intersection of the charter ids from the remaining responses (i.e. PASE and ASChart).
- The query engine now knows which charters match all the filters. However, it still needs to obtain the name and description of the charters from the project which is considered the authoritative reference for charter information.
- It consults the Cluster physical data model to determine which project is the authority for descriptive information about the requested entity type. ESawyer is the authority for CHARTER. Since ESawyer could not respond to the first round of requests we need to ask again explicitly for this information (this is the second round of requests).
- The query Engine creates a new query message from that intersection:
Second query message
- requested entity: [CHARTER]
- filter 1: [SELF.ID = {intersection of charter ids from PASE and ASChart}]
- It sends the new message to ESawyer's connector only.
- ESawyer's Connector is able to process the filter since it knows about CHARTER IDs. It uses its indices on its own XML repository to retrieve the description and URL of all the charters with ids in filter 1. It returns that result set in the response message and also says that filter 1 has been processed.
- The Query Engine inserts eSawyer's result set into this new response message:
Response message
- requested entity: [CHARTER]
- filter 1: [WITNESSED_BY.NAME = { 'Oswine' }] (PROCESSED)
- filter 2: [HAS_CLAUSE.TYPE = { 'Promulgation Place' }] (PROCESSED)
- result set:
- item 1: ['S10', 'S 10', http://www.esawyer.org.uk/content/charter/10.html, 'A.D. 689 (Canterbury, 1 March). Swæfheard (Suabhardus), king of Kent, to Æbba, abbess (of Minster-in-Thanet); grant of 44 hides (manentes) in Sudaneie in Thanet [...]']
- item 2: ['S235', 'S 235', http://www.esawyer.org.uk/content/charter/235.html, 'A.D. 688 (Besingahearh). Cædwalla, king of the (West) Saxons, to Cedde, Cisi and Criswa; grant, for the foundation of a minster, of 60 hides (cassati) at Farnham, Surrey [...]']
- The Query Engine caches the response message for optimisation purposes and returns it to the user interface
- The User Interface sees in the message that all filters have been processed, so the result is considered valid.
- It displays each item in the response result set on the HTML page for the user.
As explained in the sections above, the connector is stateless and therefore treats the first and second round of requests in the same manner: nothing in the query message tells them which round we are in. This level of complexity at which the multiple rounds and intersection occur is encapsulated entirely by the query engine and need not be considered by any of the project connectors.