The Query Structure
(PAS, GN)
Document Contents
All components in the cluster share the same data model and the query language. They are the heart of the ontological and functional integration.
Query Vocabulary
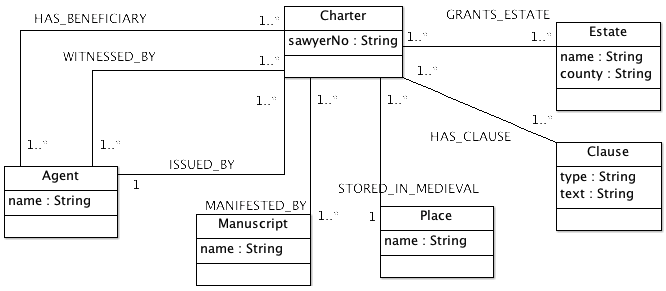
The logical data model was designed specifically for the Cluster and is described in the Modelling and System Design section; it was then converted into a Java based physical model. Its entities and relationships are therefore understood by the interface, the query engine and connectors.
The role of the connectors is to map the elements of this shared vocabulary to the project-specific data model. A particular entity such as a King or a Charter may correspond, for instance, to a record in a relational table or an XML element in an authority list.
The architecture of the Cluster ensures that this mapping is completely encapsulated by the connectors. It is therefore possible for a remote application to formulate queries or statements about the data stored within a particular Anglo-Saxon project without knowing about its logical or physical representation.
Not only does the Cluster data model permit a partial reconciliation of alternative and fragmentary views over the same application domain (i.e. Anglo-Saxon Charters) but it also allows the grouping of heterogeneous data sources, data management systems or APIs and programming frameworks behind a unified query interface.
Query Language
Search queries are expressed with the relationships (or roles) and entities (or concepts) found in the cluster data model.
For instance, to request all the charters issued by Cnut, we would formulate the query like this:
Charter query
- requested entity: [CHARTER]
- filter 1: [ISSUED_BY.NAME = {'Cnut'}]
As we can see, the query is a data structure made of two parts: a requested entity and a set of one or more filters. A filter is a condition about a property of an entity related to the requested entity. For instance, to interpret the filter in the above query it is useful to consult the data model at the top of this page and navigate from the CHARTER entity through the ISSUED_BY relationship to arrive at the AGENT entity. Only instances of AGENT whose NAME property is 'Cnut' will be considered.
More advanced queries
The language can also express more complex queries.
- Multiple filters can be specified in a query. In that case each instance returned by the cluster must match all the filters (i.e. logical AND).
- Multiple values can be specified in a single filter. If an instance in the data source matches any value in that set, the condition is met (i.e. logical OR).
- Filter values can contain wildcards: for instance, the filter [ISSUED_BY.NAME = *] means that NAME can take any value. Some connectors also accept partial wildcards such as [ISSUED_BY.NAME = 'Cn*'].
- Filter can use reverse relationships. This feature is used by the user interface to populate the various drop-down lists. For
instance, to get all possible types of clauses the user interface runs the following query: Related entity query
- requested entity: [CLAUSE]
- filter 1: [HAS_CLAUSE-.ID = {*}]
- Note the minus sign here to indicate that HAS_CLAUSE is traversed in the reverse direction, that is, from CLAUSE to CHARTER.
- A related relationship can be specified in the query. For example, if we add 'related relationship = [HAS_CLAUSE]' to the
'Charter query', the cluster will return clauses rather than charters. The query engine will hide the
internal translation of this query with a requested relationship into two separate queries. This means that
the user interface sees it as a single query, but the constituent projects see it as two independent
queries, each of which is much simpler to implement than a single complex one would be. Query with Related relationshipis equivalent to this sequence of queries:
- requested entity: [CHARTER]
- requested relationship: [HAS_CLAUSE]
- filter 1: [ISSUED_BY.NAME = {'Cnut'}]
Query 1- requested entity: [CHARTER]
- filter 1: [ISSUED_BY.NAME = {'Cnut'}]
Query 2- requested entity: [CLAUSE]
- filter 1: [HAS_CLAUSE-.ID = {charter IDs returned by Query 1}]
One of the main advantages of the modular architecture of the Cluster, and more particularly the delegation of the local processing of the query to the connectors, is that it adapts very well to a selective implementation of the query language. Indeed, if a particular connector detects that a filter is beyond the capabilities of its local data management system, it can simply mark the filter as 'unprocessed' in the response message. For example, currently only a few connectors accept wildcards, and even then only on some specific combinations of roles and attributes, but this capacity can easily be extended in future without any changes to the underlying system.
Limitations
The query language was inspired by description logics and can be viewed as a subset of this, where the formula is made of a conjunction of existential quantifiers over the value of properties attached to concepts directly related to the requested concept.
The current implementation of the query language and query engine does not allow more complex expressions such as logical combinations of filters (mixing AND and OR, using NOT or nesting subformulas) or traversal of long relationship paths within the logical data model.
Another limitation of the current implementation is that it can only return pre-formatted summaries of entity instances (consisting of a unique identifier, a human-readable identifier, a description and a URL) and not specific properties of the instances (e.g. the county for a given estate).
Some of those limitations could easily be removed by extending the query language, the query engine or the connectors. For example, we think that relatively little modification to most of those components would be required to implement a full text search across all types of entities in all projects. This type of extension would turn the search interface into something more similar to web search engines such as Bing, Google, and Yahoo, where the search input process is simpler, more intuitive and familiar to a lot of users, and the search results can contain heterogeneous objects rather than just one predefined type of entity.
Other limitations of the querying system, however, would be much more difficult to remove. Given the resemblance between the cluster query language and description logics, it is legitimate to wonder why the integration was not implemented with semantic web approaches and tools. Indeed, semantic web reasoning and querying tools would have allowed us to interrogate the distributed resources with a much more advanced and standard set of query languages and protocols. It should be noted that the present solution is not entirely incompatible with this approach as many important analytical pieces of the projects, such as the conceptual and logical modelling or the user interface, would still be completely relevant.